
L'IA générative, le droit et le contenu visuel - guide pratique de conformité juridique et de gestion des risques pour les entreprises
Petit guide pratique de conformité juridique et de gestion des risques pour les entreprises
La promesse est séduisante : générer des photos de produits en quelques secondes, automatiser l'édition d'images à grande échelle, produire des visuels marketing sans les coûts de la production traditionnelle. Les outils d'IA générative pour le contenu visuel sont passés du stade de curiosité expérimentale à celui de nécessité opérationnelle plus vite que la plupart des cadres de conformité ne peuvent s'adapter.
Si votre organisation déploie l'IA générative pour du contenu visuel, que ce soit via des outils dédiés, des fonctionnalités intégrées dans votre système DAM ou des logiciels créatifs, vous avez besoin d'une vision lucide des risques, des obligations et des questions à poser avant de passer à l'échelle. Ce guide cartographie le terrain.
Le Seuil de la Création Humaine : Quand Perdez-Vous le Droit d'Auteur ?
La question la plus fondamentale pour toute entreprise utilisant l'IA pour générer ou éditer du contenu visuel : pouvez-vous être propriétaire de ce que la machine produit ?
La réponse, dans la plupart des juridictions, est la même : la création humaine est requise pour bénéficier de la protection du droit d'auteur.
L'IA ne peut pas être auteur. Le rapport de l'U.S. Copyright Office du 29 janvier 2025 a réaffirmé que les invites seules, quelle que soit leur précision, ne constituent pas un contrôle humain suffisant pour établir la qualité d'auteur. La Cour d'appel du circuit de D.C. a confirmé cette position dans l'arrêt Thaler v. Perlmutter du 18 mars 2025.
Le Japon, la Corée du Sud, l'UE et l'Inde ont tous adopté des positions similaires. Les directives sud-coréennes d'enregistrement du droit d'auteur de juin 2025 exigent explicitement des demandeurs qu'ils documentent et distinguent les portions créées par l'humain de toute œuvre assistée par IA.
Ce que cela signifie sur le plan opérationnel :
Si vous générez une image entièrement par IA et l'utilisez dans votre marketing, vous pourriez n'avoir aucune protection par le droit d'auteur sur cet actif. Un concurrent pourrait l'utiliser sans en subir les conséquences. Si vous voulez une protection juridique, vous devez ajouter une contribution créative humaine substantielle, et vous devez documenter quelle a été cette contribution.
Toutefois, le seuil de l'aide permise par l'IA n'est pas encore précisément défini. Le Copyright Office reconnaît que l'édition assistée par IA d'une œuvre créée par un humain (par exemple, l'utilisation des outils d'IA de Photoshop pour supprimer un arrière-plan) ne retire pas le droit d'auteur de l'original. Mais la ligne entre « l'IA comme outil » et « l'IA comme créateur » demeure à évaluer au cas par cas.
Les organisations devraient établir dès maintenant des pratiques de documentation, en créant des pistes d'audit des décisions créatives humaines dans tout flux de travail assisté par l'IA.
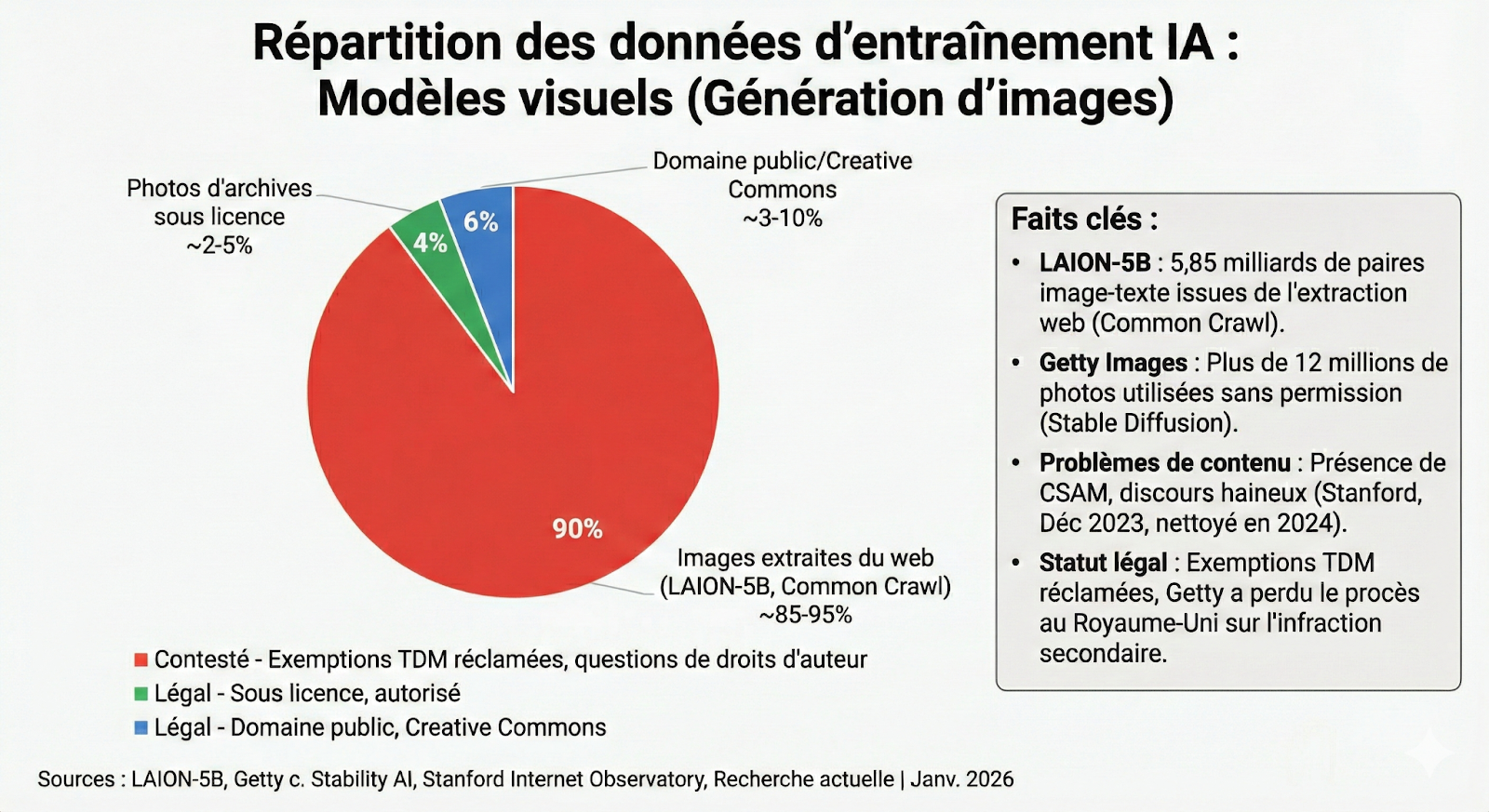
Responsabilité liée aux données d'Entraînement : le risque en amont
Vous n'avez pas collecté les données d'entraînement. Vous n'avez pas construit le modèle. Mais si le modèle que vous utilisez a été entraîné sur du contenu protégé par le droit d'auteur sans autorisation, vous pourriez être exposé.
Ce n'est pas hypothétique. Le règlement Bartz v. Anthropic en 2025, estimé à 1,5 milliard de dollars, découla d'allégations selon lesquelles l'entreprise avait téléchargé des millions de copies piratées de livres pour entraîner ses modèles. Le litige New York Times v. OpenAI se poursuit.
L'affaire Getty Images contre Stability AI se concentrait explicitement sur l'apparition de filigranes Getty dans les résultats générés, un indicateur direct de la provenance des données d'entraînement.
Le rapport du Copyright Office de mai 2025 sur l'entraînement de l'IA générative a conclu que « certaines utilisations d'œuvres protégées pour l'entraînement de l'IA générative relèveront du fair use, d'autres non ». Les tribunaux décident encore, cas par cas.
Ce que cela signifie sur le plan opérationnel :
Comprenez l'approvisionnement en données d'entraînement de votre fournisseur. Adobe commercialise explicitement Firefly comme entraîné sur du contenu sous licence et offre une indemnisation pour les entreprises.
Les pratiques d'entraînement de Midjourney font l'objet d'un examen juridique. Stability AI fait face à des litiges en cours. Le choix de votre fournisseur est une décision de gestion des risques. Demandez spécifiquement : « Quelle est la provenance de vos données d'entraînement ? Quels accords de licence sont en vigueur ? Que se passe-t-il si vos données d'entraînement s'avèrent contrefaites ?
Contrefaçon en Sortie : Marques, Droit d'Auteur et Habillage Commercial
Même si l'entraînement du modèle était licite, le résultat pourrait ne pas l'être. Les générateurs d'images IA peuvent et produisent effectivement du contenu qui contrefait des droits d'auteur, des marques et des habillages commerciaux existants, parfois avec une fidélité stupéfiante.
En juin 2025, Disney et Universal ont intenté une action contre Midjourney, alléguant que le service pouvait être sollicité pour générer des reproductions quasi identiques de personnages, dont Yoda, Bart Simpson, Iron Man et Shrek. Warner Bros. a déposé une plainte similaire en septembre. Ces affaires invoquent à la fois la contrefaçon directe (le modèle génère des résultats contrefaisants) et la contrefaçon secondaire (la plateforme permet aux utilisateurs de contrefaire).
Les implications s'étendent au-delà des personnages fictifs. Éléments de design, formes de produits, styles visuels associés à une marque, silhouettes distinctives de meubles, la courbe d'une voiture particulière, tous peuvent bénéficier d'une protection par marque ou habillage commercial. Une photo de produit générée par l’IA qui inclut, par inadvertance, des éléments de design protégés expose à la responsabilité.
Ce que cela signifie sur le plan opérationnel :
Implémentez des processus de révision pour le contenu visuel généré par l’IA. Ne présumez pas que, parce que vous n'avez pas intentionnellement sollicité un élément protégé, le résultat soit propre. Formez vos équipes à reconnaître les problèmes potentiels liés à la marque et au droit d'auteur. Examinez si votre fournisseur propose des outils pour détecter du contenu potentiellement contrefait et si ces outils fonctionnent réellement.
L'Écart d'Indemnisation : Qui Vous Couvre Vraiment ?
L'indemnisation par les fournisseurs des réclamations de propriété intellectuelle liées à l'IA est devenue un différenciateur concurrentiel. Microsoft, Adobe et Anthropic offrent une indemnisation d'entreprise sous certaines conditions. OpenAI offre une indemnisation limitée pour les clients API, Team et Enterprise. Midjourney n'en offre aucune.
Mais voici l'écart que la plupart des acheteurs d'entreprise négligent : la chaîne d'indemnisation pourrait ne pas vous atteindre.
Considérez un scénario courant : Votre organisation utilise une plateforme DAM qui a intégré l'API d'OpenAI pour alimenter ses fonctionnalités d'édition d'images. Le contrat entre le fournisseur DAM et OpenAI peut prévoir une indemnisation. Mais votre contrat est avec le fournisseur DAM, et non avec OpenAI. Votre fournisseur DAM vous transfère-t-il cette indemnisation ? Dans la plupart des cas, la réponse est non, ou la couverture est significativement plus étroite que ce qu'offre le fournisseur d'IA.
Même lorsque l'indemnisation existe, les exclusions s'appliquent. L'indemnisation d'OpenAI ne s'applique pas si : (1) vous « auriez dû savoir » que le résultat était contrefaisant, (2) vous avez désactivé les fonctionnalités de sécurité, (3) vous avez modifié le résultat ou l'avez combiné à d'autres produits, ou (4) la réclamation implique l'usage commercial d'une marque. Chacune de ces conditions limite de manière significative la protection pratique.
Ce que cela signifie sur le plan opérationnel :
Examinez chaque contrat dans la chaîne. Si votre logiciel créatif, votre système DAM ou votre plateforme marketing intègre des fonctionnalités d'IA, demandez explicitement : Votre accord avec le fournisseur d'IA inclut-il une indemnisation ? Si oui, transférez-vous une partie de cette protection à vos clients ? Quelles sont les conditions et les exclusions ? Documentez les réponses. L'absence de protection est elle-même une information dont vous avez besoin pour la gestion des risques.
Divulgation Obligatoire : Le Paysage Réglementaire Mondial
Les exigences de divulgation pour le contenu généré par l’IA ne sont plus théoriques. Plusieurs juridictions imposent désormais un étiquetage, avec davantage d'entrées en vigueur tout au long de 2026.
Union européenne : L'Article 50 de l'AI Act de l'UE exige que le contenu généré par l'IA soit « marqué dans un format lisible par machine et détectable comme artificiellement généré ou manipulé ». Les hypertrucages et les médias synthétiques utilisés à des fins publiques doivent être étiquetés. Ces exigences deviennent exécutoires le 2 août 2026. La Commission a publié son premier projet de Code de pratique sur le marquage et l'étiquetage en décembre 2025, avec des orientations finales attendues en mai 2026. Les pénalités pour non-conformité peuvent atteindre 35 millions d'euros ou 7% du chiffre d'affaires mondial.
Californie (États-Unis) : AB 853, promulguée en octobre 2025, exige des fournisseurs d'IA qu'ils intègrent des divulgations latentes (métadonnées lisibles par machine) dans le contenu généré par l'IA et qu'ils offrent aux utilisateurs l'option de divulgations manifestes visibles. La loi entre en vigueur le 2 août 2026, alignée sur le calendrier de l'UE. À partir de janvier 2027, les grandes plateformes en ligne devront détecter et afficher les données de provenance. À partir de janvier 2028, les fabricants d'appareils photo devront offrir l'intégration de la provenance pour le contenu authentique.
Corée du Sud : L'AI Basic Act est entrée en vigueur le 22 janvier 2026. Les directives d'enregistrement du droit d'auteur de juin 2025 exigent une documentation détaillée de l'usage de l'IA et de la contribution créative humaine pour les œuvres visant une protection par le droit d'auteur.
Japon : L'AI Promotion Act, adoptée en mai 2025, met l'accent sur la transparence mais adopte une approche de droit souple, non contraignante. Le cadre du droit d'auteur japonais (article 30-4) inclut des dispositions spécifiques relatives à l'entraînement de l'IA sous conditions de « non-jouissance ». Les AI Guidelines for Business recommandent de développer « des mécanismes fiables d'authentification et de provenance du contenu, lorsque c'est techniquement faisable, tels que le filigrane » pour permettre aux utilisateurs d'identifier le contenu généré par l'IA.
Inde : Les AI Governance Guidelines de novembre 2025 ne sont pas contraignantes mais signalent une direction. Les projets d’IT Rules exigeraient un étiquetage visible couvrant 10 % de la zone d’affichage pour le contenu visuel, ainsi qu’une divulgation audible pendant 10 % de la durée pour le contenu audio.
Australie et Brésil : Les deux développent activement des cadres. L'Australie a rejeté une exception de fouille de textes et de données et poursuit un régime de licence payante assorti d'exigences de transparence. Le projet de loi IA du Brésil, actuellement à la Chambre, inclut un chapitre dédié au droit d'auteur avec des régimes de rémunération pour l'utilisation des données d'entraînement.
Ce que cela signifie sur le plan opérationnel : Si vous opérez dans plusieurs juridictions, présumez que les exigences de divulgation arriveront. Les calendriers de l'UE et de la Californie sont fixés. Construisez dès maintenant des processus pour suivre le contenu généré par l’IA et assurez-vous que vos systèmes peuvent intégrer les métadonnées requises. Considérez les outils et les flux de travail conformes au C2PA comme un standard de facto.
Protéger Vos Propres Actifs : La Question de la Collecte
La question de la responsabilité fonctionne dans les deux sens. Si les entreprises d'IA sont confrontées à des conséquences liées à l'entraînement sur du contenu non autorisé, vos actifs pourraient risquer d'être collectés pour le modèle de quelqu'un d'autre.
En 2025, plusieurs éditeurs de presse français et allemands ont intenté des actions collectives contre OpenAI et Google pour l'utilisation non autorisée de contenus journalistiques dans l'entraînement de leurs modèles. Le syndicat européen des éditeurs de presse a déposé des plaintes formelles auprès de la Commission européenne, invoquant des violations de la Directive sur le droit d'auteur sur le marché unique numérique.
En Italie, les principaux groupes médias ont obtenu des injonctions préliminaires contre plusieurs plateformes d'IA générative. Les lobbies des industries créatives européennes ont réussi à faire inscrire dans l'AI Act des garde-fous stricts sur l'utilisation des œuvres protégées, arguant que l'absence de consentement équivaudrait à une « expropriation numérique
Ce que cela signifie sur le plan opérationnel : Auditez votre exposition. Où vos actifs visuels sont-ils publiés ? Quelles protections techniques (robots.txt, blocages spécifiques à l'IA, RSL) sont en place ? Vos conditions d'utilisation abordent-elles l'utilisation de l'IA pour l'entraînement ? Certaines plateformes, comme Stability AI, ont mis en place des mécanismes d'exclusion. Si vos actifs visuels ont une valeur commerciale, l'absence de mesures de protection peut elle-même créer un risque à mesure que les cadres de licence se développent.
Où Votre Organisation Devrait-Elle Se Situer ? Un Cadre de Maturité
Les questions ci-dessus ne sont pas des cases de conformité « oui » ou « non ». Elles représentent un spectre de capacités organisationnelles. Le Modèle de Maturité en Authenticité et Provenance du Contenu fournit un cadre pour évaluer où se situe votre organisation et où elle doit aller.
Aux niveaux de maturité les plus bas, les organisations n'ont aucune approche systématique de la provenance du contenu. Elles ne peuvent pas répondre aux questions de base : Lesquels de nos actifs publiés ont été générés par l’IA ? Quelles données d'entraînement les modèles que nous utilisons ont-ils sourcées ? Quelles métadonnées sont intégrées dans nos résultats ? Ces organisations sont confrontées au risque réglementaire et juridique le plus élevé.
Aux niveaux de maturité supérieurs, les organisations ont mis en place un suivi systématique de la provenance tout au long du cycle de vie de leur contenu. Elles peuvent démontrer la création humaine pour le travail protégé par le droit d'auteur, documenter les pratiques de données d'entraînement de leurs fournisseurs, examiner les résultats pour le risque de contrefaçon et intégrer les métadonnées requises avant publication. Ces capacités ne sont pas des fonctionnalités optionnelles. Elles deviennent des exigences de base pour opérer sur des marchés réglementés.
Points de départ pratiques :
- Inventoriez chaque outil de votre flux de travail qui utilise l'IA générative, qu'il soit dédié ou intégré. Pour chacun, documentez : la provenance des données d'entraînement (dans la mesure du connaissable), les termes d'indemnisation et la chaîne de couverture, les capacités de divulgation des résultats et les restrictions d'usage.
- Établissez des pratiques de documentation pour la contribution créative humaine dans le travail assisté par l’IA. Si vous voulez bénéficier de la protection du droit d'auteur, vous avez besoin de preuves de ce que l'humain a fait.
- Implémentez des processus de révision pour le contenu visuel généré par l'IA avant publication, avec une attention spécifique aux préoccupations de marque, de droit d'auteur et de sécurité de la marque.
- Évaluez la préparation de votre organisation aux exigences de divulgation de métadonnées. Vos systèmes peuvent-ils intégrer des données de provenance conformes au C2PA ? Sinon, quel est le chemin vers la capacité ?
- Auditez l'exposition de vos propres actifs à la collecte de données d'entraînement et mettez en place les protections appropriées.
Ce Qui Vient Ensuite
Le paysage continuera d'évoluer. Le Code de pratique de l'UE relatif au marquage du contenu IA sera finalisé d'ici mi-2026. Le litige entre Disney et Midjourney produira un précédent. Le cadre de licence australien prendra forme. Les États-Unis pourraient envisager une action fédérale.
Mais la direction est claire : la transparence, la responsabilité et la provenance deviennent obligatoires, et non optionnelles. Les organisations qui développent ces capacités maintenant seront positionnées pour la conformité. Celles qui attendent se démèneront pour adapter rétroactivement les systèmes et pratiques sous pression réglementaire.
La technologie avance vite. Le droit rattrape son retard. Vos pratiques opérationnelles doivent être en avance sur les deux.
Version + DAM et + France:

IA générative et contenu visuel : guide juridique de conformité pour utilisateurs de DAM
L'intégration de l'intelligence artificielle générative dans les workflows visuels d'entreprise crée cinq zones de risque juridique distinctes. Pour les équipes qui gèrent des milliers d'actifs via des systèmes DAM, comprendre ces risques n'est plus optionnel.
1. Seuil de Création Humaine
Aux États-Unis comme en Europe, seule une personne physique peut être auteur. Une œuvre générée sans intervention humaine significative ne bénéficie d'aucune protection par le droit d'auteur.
Le tribunal du district de Columbia a confirmé en août 2023 le rejet du US Copyright Office dans l'affaire Thaler v. Perlmutter : un contenu produit par IA sans apport créatif humain identifiable ne répond pas aux critères classiques de protection. Le Parlement européen, dans son étude "Generative AI and Copyright" (juillet 2025), souligne l'incertitude entourant le statut des contenus générés et appelle à une clarification du cadre, tout en préservant la protection des auteurs humains.
En France, le rapport du Sénat n° 842 (9 juillet 2025) réaffirme que les contenus générés par IA ne devraient pas pouvoir bénéficier du régime de la propriété intellectuelle. Le Conseil Supérieur de la Propriété Littéraire et Artistique a confié une mission à la professeure Alexandra Bensamoun le 20 juin 2025, avec des conclusions attendues à l'été 2026.
Pour les utilisateurs de DAM : Si votre workflow repose uniquement sur des prompts basiques sans sélection, retouche ou composition significative, vos actifs générés ne sont probablement pas protégeables. Documentez l'intervention humaine à chaque étape : prompts sophistiqués, itérations, sélections, retouches.
2. Responsabilité liée aux Données d'Entraînement
L'IA générative s'entraîne sur des corpus massifs, incluant souvent du contenu protégé sans autorisation. Plusieurs actions en justice illustrent ce risque :
La décision GEMA c/ OpenAI (Tribunal de Munich, 11 novembre 2025) a qualifié pour la première fois la mémorisation interne de contenus protégés au sein des paramètres d'un modèle d'IA de reproduction au sens de la directive 2001/29/CE. En France, l'Autorité de la concurrence a infligé une amende de 250 millions d'euros à Google pour l'utilisation d'articles de presse sans permission dans l'entraînement de Gemini.
Aux États-Unis, l'affaire Thomson Reuters v. Ross Intelligence (11 février 2025) a établi qu'utiliser du contenu protégé pour construire un produit concurrent constitue une violation du fair use. À l'inverse, dans Kadrey v. Meta, le juge a estimé que l'utilisation de livres pour entraîner les modèles Llama était "hautement transformative" – mais cette jurisprudence reste en appel.
Le US Copyright Office a publié en mai 2025 son rapport final sur l'entraînement des IA génératives, concluant qu'"il n'est pas possible de préjuger des résultats des litiges" et que "certaines utilisations d'œuvres protégées pour l'entraînement d'IA générative relèveront du fair use, et d'autres non."
Pour les utilisateurs de DAM : Vérifiez si votre fournisseur DAM ou les outils d'IA intégrés divulguent la provenance de leurs données d'entraînement. La plupart ne le font pas. L'opacité sur les corpus d'entraînement vous expose à des risques juridiques inconnus.
3. Contrefaçon en Sortie
Même si l'entraînement était légal, les sorties générées peuvent violer des droits d'auteur. Les modèles peuvent reproduire des éléments substantiels d'œuvres du corpus d'entraînement, créant un risque de contrefaçon directe.
Dans Andersen v. Stability AI, les plaignants allèguent que Stable Diffusion peut générer des images qui violent leurs droits. Le Copyright Office américain note dans son rapport de mai 2025 que les modèles d'IA peuvent "mémoriser et régurgiter de longues séquences ou images provenant des données d'entraînement, y compris du contenu potentiellement protégé par le droit d'auteur."
Pour les utilisateurs de DAM : Avant de publier du contenu généré par IA, effectuez des recherches d'images inversées et des vérifications de similarité. Intégrez des workflows de révision juridique pour les actifs destinés à un usage commercial. Créez des champs de métadonnées spécifiques : outil utilisé, prompt, numéro de série, statut de vérification.
4. Écart d'Indemnisation
La majorité des fournisseurs d'outils d'IA générative n'offrent aucune indemnisation pour les réclamations de propriété intellectuelle. Certaines plateformes enterprise (OpenAI, Microsoft, Google Cloud) fournissent des indemnisations contractuelles, mais avec des exclusions importantes et des plafonds.
Pour les utilisateurs de DAM : Examinez attentivement vos contrats. La plupart des systèmes DAM qui intègrent des fonctionnalités d'IA générative ne fournissent pas d'indemnisation propre et s'appuient sur des intégrations tierces. La responsabilité légale reste généralement avec vous, l'utilisateur final.
Demandez explicitement :
- Votre fournisseur DAM offre-t-il une indemnisation pour le contenu généré par IA ?
- Les outils d'IA intégrés sont-ils couverts par des garanties d'indemnisation ?
- Quelles sont les exclusions et les plafonds ?
-

5. Divulgation Obligatoire
Plusieurs juridictions imposent désormais la divulgation du contenu généré par IA :
Union Européenne : L'AI Act (Règlement 2024/1689), dont les premières mesures se sont appliquées depuis le 2 février 2025, impose aux systèmes d'IA générative d'indiquer clairement les sources d'entraînement et de mettre en place des mécanismes de traçabilité des œuvres utilisées.
États-Unis - Californie : AB 853 (entrée en vigueur janvier 2025) exige que le contenu électoral ou électeur généré par IA soit étiqueté. Les violations entraînent des amendes civiles.
Corée du Sud : La loi sur la promotion de l'industrie de la radiodiffusion vidéo en ligne exige depuis 2024 que les deepfakes soient étiquetés.
Japon : Les directives de l'Agence des Affaires Culturelles (2024) encouragent la divulgation volontaire du contenu généré par IA.
Inde : Les règles IT de 2023 exigent que les plateformes de médias sociaux étiquètent le contenu généré par IA.
Pour les utilisateurs de DAM : Mettez en place des systèmes de marquage automatique pour tout contenu généré par IA. Créez des champs de métadonnées dédiés et des workflows d'approbation avant publication. La non-conformité aux lois de divulgation peut entraîner des sanctions réglementaires.
6. Protection des Actifs Contre la Collecte
La proposition de loi sénatoriale française (12 décembre 2025) relative à "l'instauration d'une présomption d'exploitation des contenus culturels par les fournisseurs d'intelligence artificielle" témoigne d'une volonté de rééquilibrer les rapports entre titulaires de droits et fournisseurs d'IA. Le rapport du Sénat n° 842 plaide pour une transparence intégrale des corpus et un droit à rémunération effectif des créateurs.
Pour les utilisateurs de DAM : Protégez vos actifs visuels propriétaires contre la collecte non autorisée. Implémentez des standards C2PA pour l'authentification du contenu. Utilisez des watermarks Imatag ou similaires pour la traçabilité. Configurez des en-têtes HTTP appropriés et des fichiers robots.txt pour bloquer les crawlers d'IA comme RSL.
Certains systèmes DAM offrent des options de consentement avant entraînement ou des mécanismes d'opt-out. Vérifiez si votre plateforme les propose et activez-les.
Conclusion
Les systèmes DAM facilitent la gestion de milliers d'actifs visuels, mais la plupart n'offrent pas de protection juridique intrinsèque contre les risques liés à l'IA générative. La responsabilité repose sur vous.
Cinq actions essentielles :
- Documentez l'intervention humaine pour maintenir la protection par droit d'auteur
- Vérifiez la provenance des données d'entraînement des outils que vous utilisez
- Implémentez des workflows de vérification avant publication
- Exigez la transparence contractuelle sur l'indemnisation
- Respectez les obligations de divulgation selon vos juridictions
Le paysage juridique de l'IA générative évolue rapidement. Les décisions de 2025 en France, en Europe et aux États-Unis ne seront pas le dernier mot. Restez vigilants, documentez vos processus, et n'assumez jamais que votre infrastructure technologique vous protège automatiquement.







